Sonnet 4.6이 떴다 — Opus급 성능을 1/5 가격에
Sonnet 4.6이 나왔다
2월 17일, Anthropic이 Claude Sonnet 4.6을 공개했다.
Opus 4.6이 나온 지 불과 12일 만이다. 그리고 이번 Sonnet은 단순한 마이너 업그레이드가 아니다.
숫자가 말해주는 것
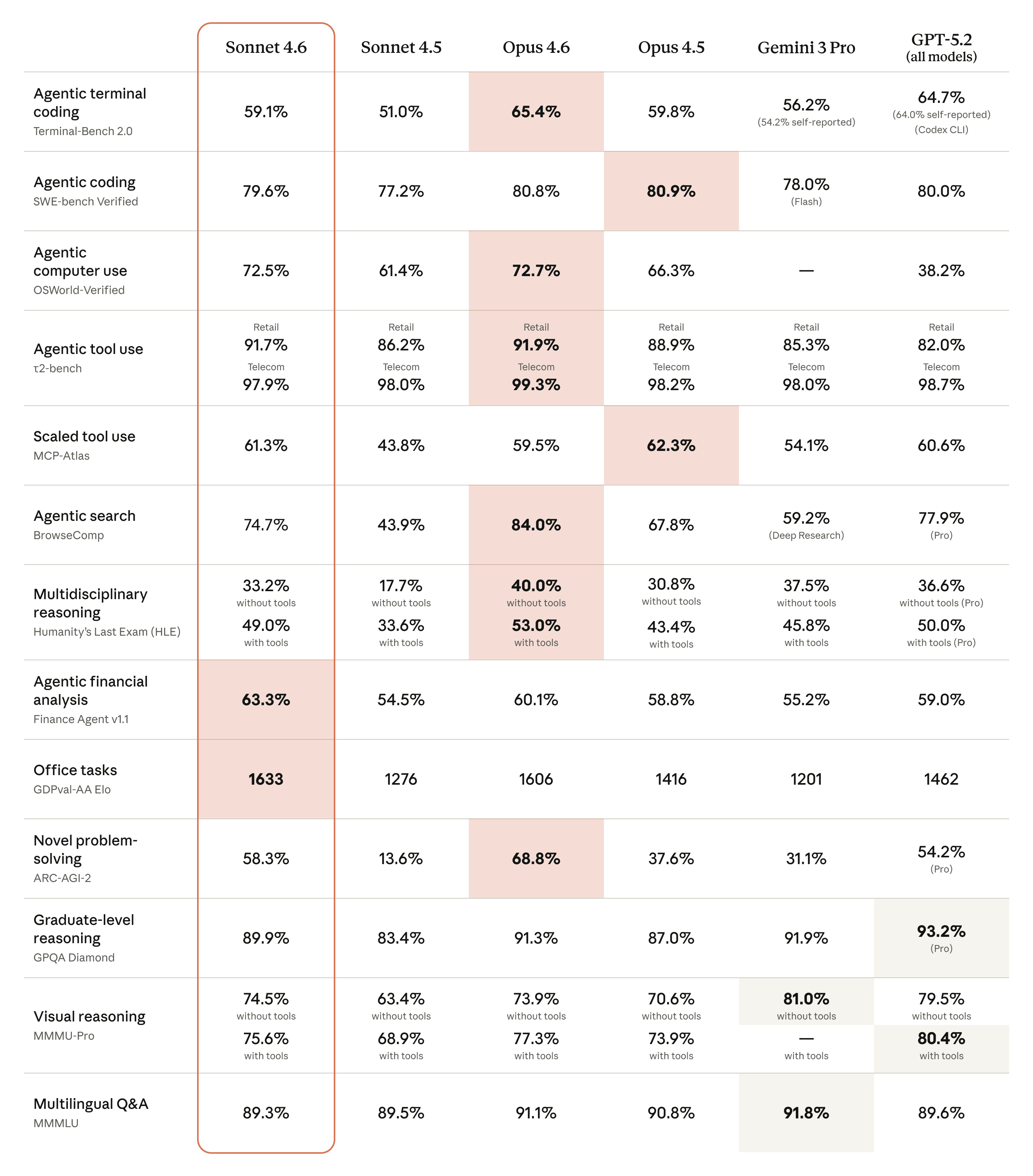
핵심 벤치마크를 보자.
| 벤치마크 | Sonnet 4.6 | Opus 4.6 | GPT-5.2 |
|---|---|---|---|
| SWE-bench (코딩) | 79.6% | 80.8% | 80.0% |
| Finance Agent v1.1 | 63.3% 🏆 | 60.1% | 59.0% |
| GDPval-AA Elo (오피스) | 1633 🏆 | 1606 | 1462 |
| OSWorld (컴퓨터 사용) | 72.5% | — | 38.2% |
| Terminal-Bench 2.0 | 59.1% | 65.4% | — |
| GPQA Diamond (추론) | 89.9% | 91.3% | — |
Sonnet이 Opus를 이기는 영역이 있다. 금융 분석과 오피스 태스크에서는 Sonnet이 1등이다.
코딩(SWE-bench)도 79.6% vs 80.8%로 거의 동급. 1.2%p 차이에 5배 가격 차이라면, 대부분의 프로덕션 워크로드에서 Sonnet을 선택하는 게 합리적이다.
아래는 Anthropic 공식 벤치마크 이미지다:
컴퓨터 사용 능력: 14.9% → 72.5%
가장 인상적인 건 OSWorld 벤치마크다.
- 2024년 10월 (Sonnet 3.5): 14.9%
- 2026년 2월 (Sonnet 4.6): 72.5%
16개월 만에 5배 가까이 뛰었다.
복잡한 스프레드시트 완성, 멀티스텝 웹 폼 탐색 같은 작업에서 인간 수준의 성능을 보인다고 한다. GPT-5.2의 38.2%와 비교하면 압도적이다.
자동화 워크플로우를 설계하는 입장에서 이건 실질적인 의미가 있다. 코드만 짜는 에이전트가 아니라, 화면을 보고 직접 조작하는 에이전트가 현실이 되고 있다.
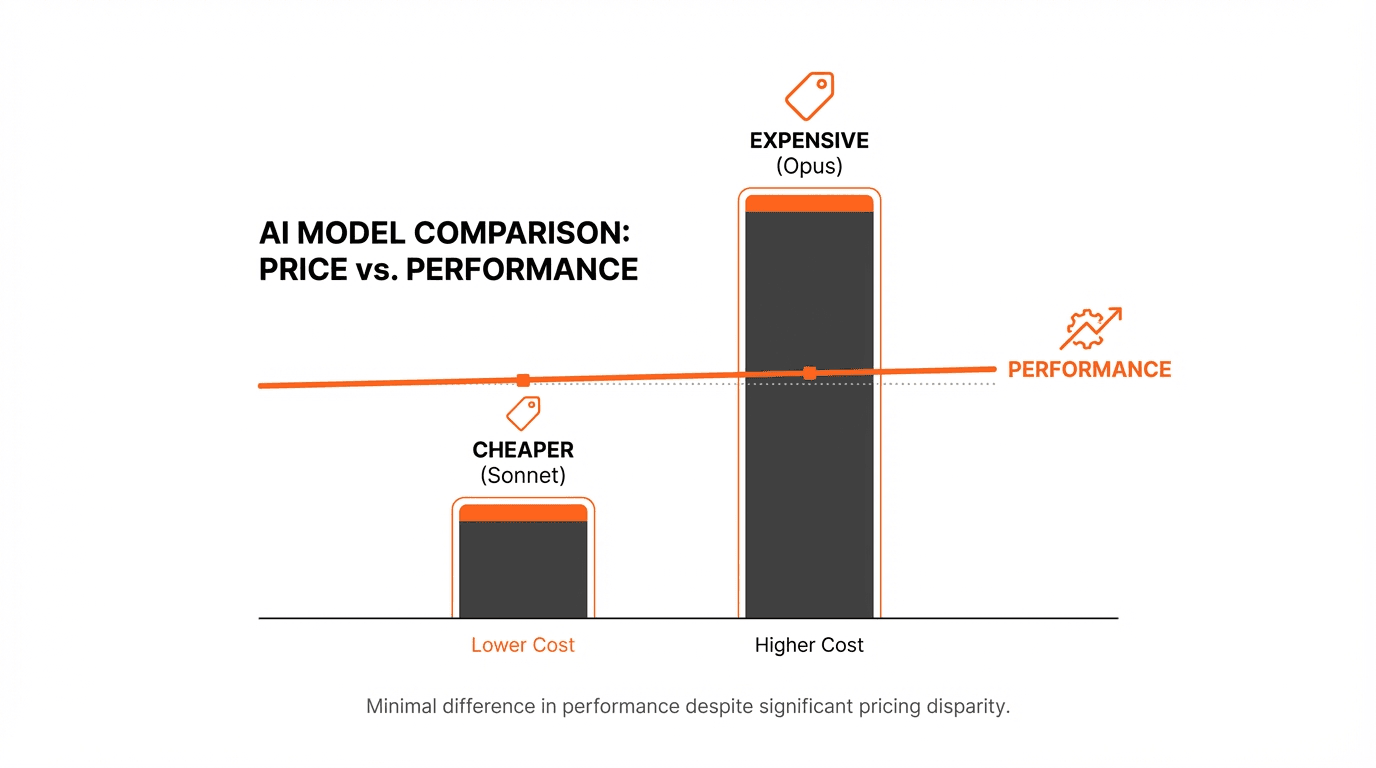
가격: 변함없이 $3/$15
| 모델 | Input (1M 토큰) | Output (1M 토큰) |
|---|---|---|
| Sonnet 4.6 | $3 | $15 |
| Opus 4.6 | $15 | $75 |
Sonnet 가격은 4.5와 동일하다. 성능만 올리고 가격은 그대로.
추가로:
- 1M 토큰 컨텍스트 윈도우 (베타)
- 무료 티어 기본 모델 승격 (파일 생성, 커넥터, 스킬, 컴팩션 포함)
- Claude Code, API, Cowork 전 플랫폼 즉시 사용 가능
커뮤니티의 냉정한 반응
Reddit r/ClaudeCode에서 358 업보트를 받은 이 글의 댓글은 흥미롭다. 마냥 환호하지 않는다.
”GPT 5.3이 빠졌는데?”
“Straw man comparison to GPT 5.2 when GPT 5.3 has been out just as long as Opus 4.6”
벤치마크 비교에서 GPT 5.3을 빼놓은 건 의도적이라는 지적. 공정한 비교가 아니라는 것.
”Opus와 GPT-5.2 차이는 무시할 수준인데 가격은 10배”
“The elephant in the room is that the performance difference between Opus 4.6 and GPT-5.2 is negligible while the latter costs 10x less… I love Claude and use it for all my work, but something will have to change.”
Claude 충성 유저조차 가격 경쟁력에 대한 우려를 표하고 있다.
”벤치마크는 의미 없다”
“Those benchmarks … they are truly meaningless. Just based on Gemini 3 Pro near same level as GPT 5.2 and Opus 4.5 — while in reality Gemini is 10x less suitable for real coding.”
벤치마크 숫자와 실사용 경험의 괴리. 이건 모든 AI 모델 발표 때마다 반복되는 논쟁이다.
”Claude Code 토큰이 너무 빨리 떨어진다”
“I literally cannot run out of Codex tokens. I’ve tried! But Claude runs out after an hour of work. On the $20 plans.”
OpenAI Codex와의 직접 비교. 모델 성능이 아니라 사용량 제한이 실제 개발자 경험을 좌우한다는 지적.
실사용자 관점에서
나는 현재 PM 에이전트에 Opus, Dev/QA 에이전트에 Sonnet을 쓰고 있다. Sonnet 4.6의 벤치마크가 사실이라면:
- Dev 에이전트의 코드 품질이 눈에 띄게 올라갈 수 있다 — SWE-bench 79.6%는 이전 Sonnet 대비 유의미한 향상
- 컴퓨터 사용 능력은 QA 에이전트에 직접적 임팩트 — 스크린샷 기반 테스트 자동화 가능성
- 1M 토큰 컨텍스트는 “One Session Strategy”와 궁합이 좋다 — PRD 전체를 한 세션에 넣고 작업 가능
다만 커뮤니티 반응처럼, 벤치마크와 실사용은 다를 수 있다. 며칠 써보고 판단해야 한다.
정리
Sonnet 4.6은 **“Opus급 성능을 Sonnet 가격에”**라는 약속을 숫자로 보여줬다.
하지만 진짜 질문은 이거다:
벤치마크에서 1-2%p 차이가, 내 프로덕션 파이프라인에서도 1-2%p 차이일까?
그건 써봐야 안다.